
TTA LIGHTNING SURVEY: Results Are In!
Last month, TTA sent out an industry-wide call to production music libraries, asking you all for your best and worst experiences with music metadata. (If you haven’t contributed yet, we’d still love to hear from you!!)
TagTeam is lucky enough to sit at the intersection of several industries—music, tech, film/TV, speculative spreadsheet stockpiling—and as the years have gone by it’s only become more apparent how much we learn from the varied perspectives of our many lovely clients.
By nature of how our services are structured, we regularly come into contact with all types in production music, from the smallest of single-composer libraries to some of the largest rights holders in our industry, and as a result it’s our business to be flexible to the many needs and concerns of everyone in this space, not just those with the most tracks or highest budgets.
With that in mind, we saw it as a unique opportunity for us to bring together as many as we could to discuss some of the biggest concerns and problems facing music search and metadata—with the not-so-hidden motive that, if we could, we’d love to help solve some of them. (For more info on TagTeam’s growing roster of metadata and software solutions, see here and here.)
So let’s see what you all had to say!
PART I – Demographics
We wanted to get a sense of whose feedback we were getting, so perhaps the most relevant question to the rest of the survey was the one we put at the very end:
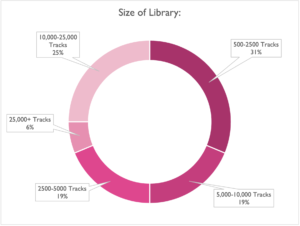
Our turnout here pretty closely reflects the diversity in clients we work with regularly, with a decent spread of voices from the very small up to the much larger, and on average just under 10,000 tracks. (Thank you again to everyone who took part!)
We were especially glad to see that our survey reached a wide cross section of the industry, and thus (hopefully) was that much more representative as a result.
Another burning demographic question we had was about the usage of different online platforms:
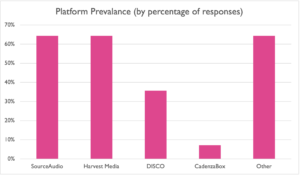
It’s important to note that this section included the option for multiple selections—so over 60% of the responses mentioned using SourceAudio, Harvest, and/or other platforms, including SynchTank, SoundMiner, various subpublishers and distributors, as well as P2P delivery via Dropbox and other file sharing services.
This also matched our experience based on the number of deliveries we do for SourceAudio and Harvest Media, DISCO being an ever more popular runner-up as well. We also suspect that if we had included an option for P2P file delivery platforms like Dropbox or WeTransfer, we might have seen more responses in that category (though those were less relevant to the search-related questions in our survey).
Lastly, the first question we asked everyone, and the most relevant to our sense of self-importance in this industry:
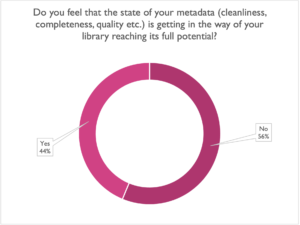
Sounds like there might be some work for us yet!
(Although glad to hear that many of us are managing fairly well!)
PART II – Types of Search
There was a lot to dig into when it came to descriptive metadata, so we’ll try to spend most of our time on some of the more interesting results.
One meta-level question we set out to answer was whether libraries’ internal use of metadata differed much from the intended client use of metadata, the idea being that perhaps there were certain types of metadata better suited for in-company use, or others that were more valuable in client-facing search contexts.
We included two separate survey sections, each covering the same types of metadata, but asking how much each category of data mattered either to your *internal* use as a company (i.e. helping you responding to briefs, assemble playlists for potential clients, track down the best selections etc.), or to your prospective client’s use (for their ease of navigating your library and finding the best music themselves).
With a slight skew placing importance towards the client-side, the results were largely similar for most categories of metadata:
Internal Use
Client Use
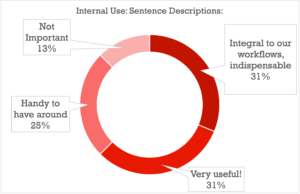
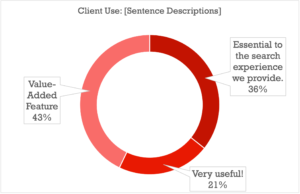
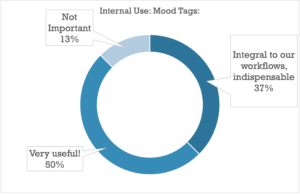
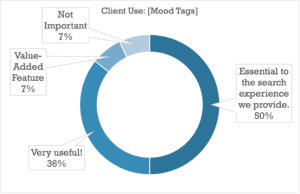
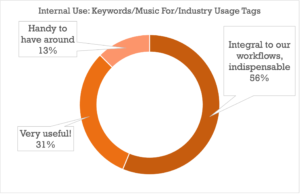
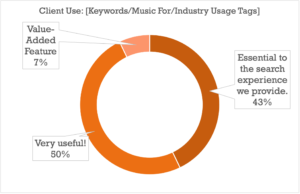
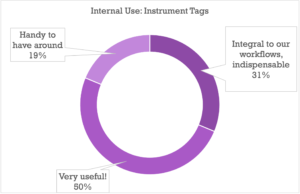
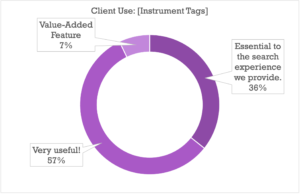
It comes as no surprise that once clients get involved, the bar gets higher on the metadata you present to them directly: tags that are “Very Useful” to a library owner who knows their own catalog will in all likelihood be essential to the search experience of someone just starting to find their way around, with the “Handy to Have Around” tags proving to be Very Useful as well (good tip for anyone thinking of taking their catalog public).
There were some interesting subtleties on the relative importance of each category of metadata, but by and large the data strongly shows that all of the above categories are at the very least highly important when it comes to providing a complete search strata for your clients or your team.
There were a few notable exceptions, like Writer/Publisher metadata, which skewed towards Internal Use being more important (indicating cases where payouts and royalties are perhaps more often handled by the library/publisher), and Album Descriptions, Album Tags, and Playlists which split pretty much evenly between Internal and External importance (though both ranked high on the usefulness index as well).
We would have loved to have surveyed the hypothetical clients in these scenarios as well, for an undoubtedly interesting series of charts comparing the end-user’s perceptions on music metadata to the libraries’ perceptions, so if anyone has an active listserv of music supes and editors who might be interested, we’d happily put together round two, if only to satiate our own curiosity.
PART III – PROBLEMS
On to the juicy part—we asked you what the worst offenders were when it came to metadata problems in your library.
Being a company that sells products and services designed to solve these kinds of problems these questions were definitely a little self-serving, but we’d also like to believe that this is gives us all a glance at issues we ALL face (and can maybe feel a little better about not having 100% perfect handle on).
To that end, we’ll say whoever has issues with incomplete Writer and Publisher information in your metadata: you aren’t alone.
Missing or Inaccurate Writer/Publisher Info ranked highest of all with 46% of you saying that this issue was “An Absolute Nightmare”:
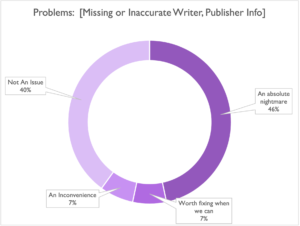
(Though it also appears that those that have it together really have it together. Something we can all aspire to I guess.)
Tied for second place were both the Quality and Completeness of descriptive metadata, with a Nightmare Score of 31%, and a Worth-Fixing-When-We-Can score of 44% (a combined total of 75%):
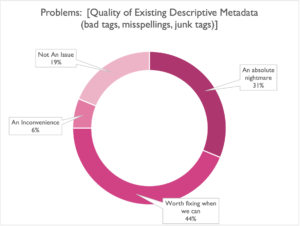
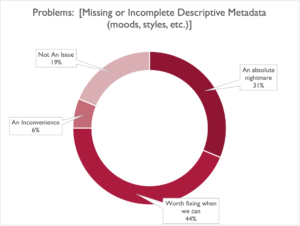
This covers everything from tracks with missing descriptive metadata, only partial descriptive metadata, and tracks whose metadata might as well not be there for its issues with quality control. Again, this seems to be an issue plaguing libraries large and small, so if this sounds familiar, you can definitely take some comfort in knowing you’re not the only one.
Runners up included Missing or Inaccurate Track/Release Info (Nightmare score of 19%, WFWWC Score of 31%), Poorly Titled Tracks (25 and 13 percent, respectively) and large scale inconsistencies in metadata as a result of mergers/acquisitions (19 and 25 percent).
The Distro side of things had some definite red flags as well, like the 75% of you who had major problems keeping metadata in sync between platforms and subpubs (definitely tough to manage):
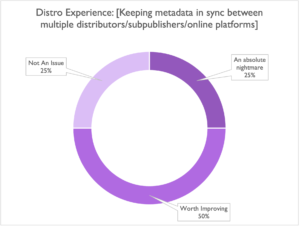
Over half of you also mentioned that just having to export the same metadata for multiple subpublishers/platforms at all was a headache, and for some, a pretty darn bad headache.
PART IV – SOLUTIONS
There were some final questions on the survey gauging interest in potential products we are working on (looking at you, missing/incomplete metadata), but before we got to that, we had to address the elephant in the room: AI.
As we’ve made a point of repeating for as long as we’ve been running our blog and newsletter, TagTeam Analysis is first and foremost a human-listening based metadata company. We’re not afraid of AI, and frankly have done plenty of work with it (or more accurately, its close cousin Machine Learning) in order to better assess its potential for helping our taggers do their work faster, and more accurately.
We have our opinions on the role and effectiveness of AI/Machine Learning in music metadata, but we had to know how YOU felt. Survey says:
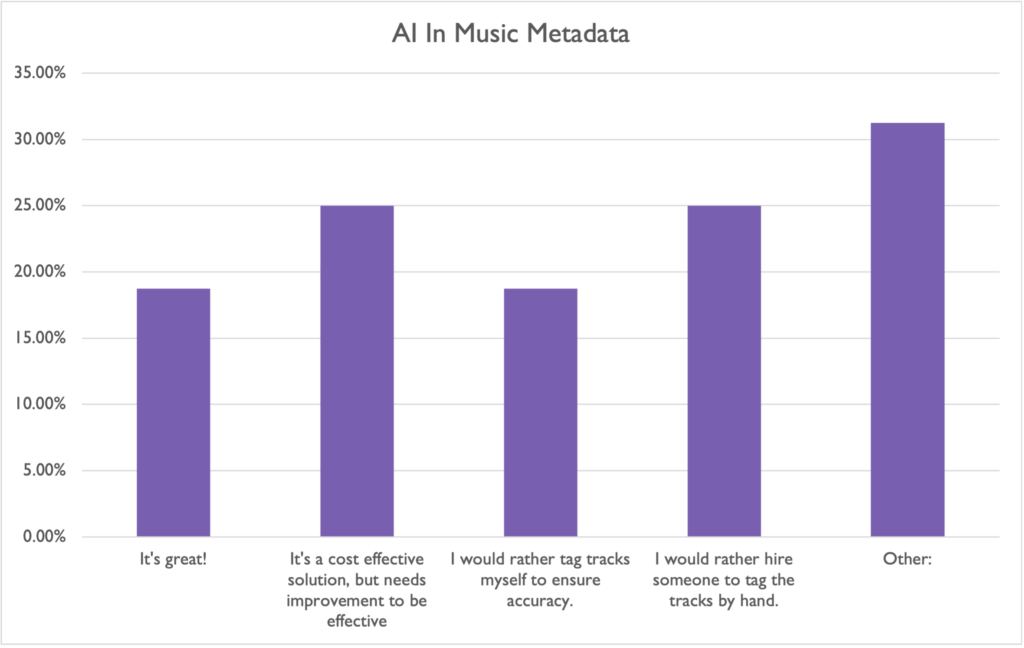
(This was also a question that left room for multiple selections, so percentages are based on the number of responses that included any of the above.)
The range of responses in the “Other” category included:
– “We have a lot of sound design elements. AI is just not up to par in describing things accurately at this point.”
– “Its often Lacks the Human intution of Human Listening. and gets too generic.”
– “It’s not much cheaper than humans right now.”
– “I love the idea of it… and ultimately that is where we are headed, but its currently too expensive and not reliable.”
– “Hmmmmmmmm”
Based on our experience, we’re inclined to agree with all of the above. Indeed, we see ML as a powerful new technology with lots of potential, and one that is already securing a foothold in our industry via the likes of Similarity Search, DISCO Autotag, and many other enterprise level solutions. What we don’t see in ML/AI at this time is any kind of Silver Bullet search solution that completely eliminates the need for human listening. And from the looks of it, many of you don’t either.
So! If Machine Learning isn’t here to magically eliminate any of the many problems we went over above, what can TTA bring to the table?
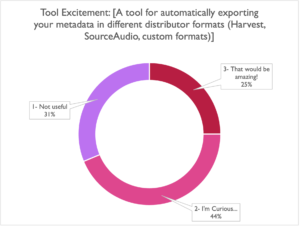
Those of you who have worked with us on deliveries know that TTA has a few tricks up its sleeve when it comes to exporting in multiple publisher formats. Our online tagging platform TuneTagger currently supports metadata exports in a few select formats (Harvest and Source being the main ones), but it looks to us like a more comprehensive solution would do well on our roadmap.
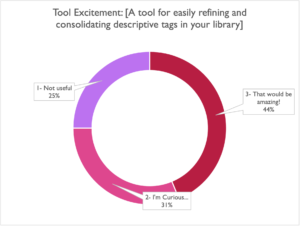
Editor’s note: a tool solving this exact problem has been a pet project of mine for some time now, and besides being something that would be immensely valuable to some people, I also have a vision for how it could be something fun and aesthetically satisfying (at least for those who take joy in refining data). I will happily report more when I make more progress on this.
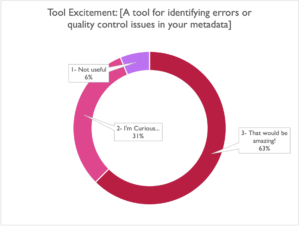
This one to us seems too important to ignore. We have many internal strategies for dealing with these problems on databases big and small, but translating our processes into a straightforward web or software solution will be worth taking the time to get right.
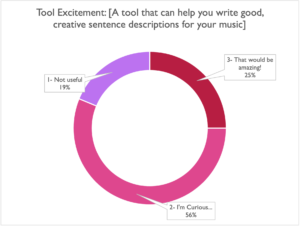
Proud to announce that we’ve just put our New and Improved Sentence Builder into production on TuneTagger! We were glad to see the curiosity, and anyone who wants a demo is welcome to reach out to us on our contact page.
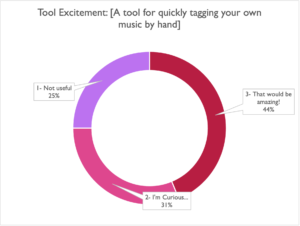
Trick Question! TuneTagger is the fastest, most easily customizable way to tag your music by hand, with a whole range of features like Dropbox Track Sync, predictive tagging (for certain taxonomies), alt/stem editing tools, multiple export formats and more. It’s also the same platform we use internally to tag thousands of tracks a year and priced according to the number of tracks you expect to tag.
Reach out to us for more info!
Once again we need to thank everyone who contributed to our survey, as well as to our many clients whose insight through the years has given us invaluable direction in this space. We hope the results here help in some small way to contribute to the conversation around the problems we continue to tackle as a community in production music search.
Cheers!
About Us:
Tagteam Analysis offers music tagging and metadata services to companies and libraries in need of advanced music search tools and optimization. Read more about us on our website: tagteamanalysis.com


